Kite Dataset Lifecycle
Datasets have a fairly predictable lifecycle: creation, population, validation, modification, and, ultimately, annihilation.
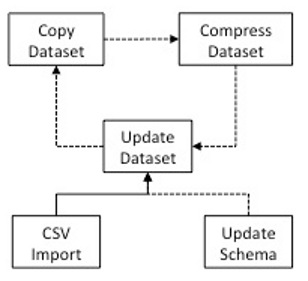
In truth, the lifecycle looks something like this.
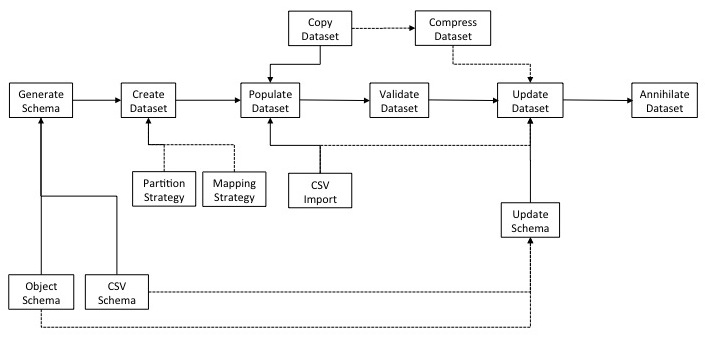
For the sake of simplicity, let’s break it down into six general steps.
- Generate a schema for your dataset.
- Create the dataset.
- Populate the dataset.
- Validate the dataset.
- Update the dataset.
- Annihilate the dataset.

Preparation
If you have not done so already, install the Kite command-line interface.
Generate a Schema for the Dataset
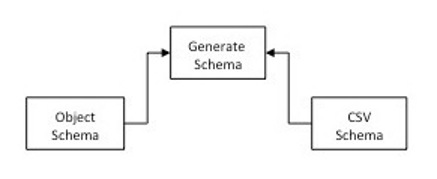
You define a Kite dataset using an Avro schema. The schema defines the fields for each row in your dataset.
You can create the schema yourself as a plain text file. Avro schema syntax is designed to be concise, rather than easy to read. It can be tricky to create and troubleshoot a schema definition. See Defining a schema in the Apache Avro documentation for more information on writing your own Avro schema.
In most cases, it’s easier to generate a schema definition than to create one by hand. You can generate an Avro schema based on a Java object or a CSV data file.
Inferring a Schema from a Java Class
You can use the CLI Command object-schema to infer a dataset schema from the instance variable fields of a Java class. Classes are mapped to Avro records. Avro reflect only supports concrete classes with no-argument constructors. Avro reflect includes all inherited fields that are not static or transient. Fields cannot be null unless annotated by Nullable or a Union containing null.
For example, the following code sample excerpts the pertinent lines from a class that defines a Java object that describes a dataset about movies.
1 2 3 4 5 6 7 8 9 10 11 |
package org.kitesdk.examples.data; /** Movie class */ class Movie { private int id; private String title; private String releaseDate; . . . public Movie() { // Empty constructor for serialization purposes } |
Use the CLI command obj-schema to generate an Avro schema file based on the source Java class.
kite-dataset obj-schema org.kitesdk.cli.example.Movie -o movie.avsc
The CLI uses the names and data types of the instance variables in the Java object to construct an Avro schema definition. For the Movie class, it looks like this.
1 2 3 4 5 6 7 8 9 10 |
{
"type":"record",
"name":"Movie",
"namespace":"org.kitesdk.examples.data",
"fields":[
{"name":"id","type":"int"},
{"name":"title","type":"string"},
{"name":"releaseDate","type":"string"},
]
}
|
For more insight into Avro reflection, see the Javadoc entry for Avro reflect.
Inferring a Schema from a CSV File
The Kite CLI can generate an Avro schema based on a CSV data file.
The CSV data file for the Movie dataset might start off like this.
id, title,releaseDate
1,Sam and the Big Dog,"August 14, 2014"
2,Crocophiles,"November 18, 1995"
. . .
Use the CLI command csv-schema to generate the Avro schema.
kite-dataset csv-schema movie.csv --class Movie -o movie.avsc
The Kite CLI infers field names from the values in the first row and data types from the values in the second row of the CSV file.
1 2 3 4 5 6 7 8 9 10 |
{
"type":"record",
"name":"Movie",
"namespace":"org.kitesdk.examples.data",
"fields":[
{"name":"id","type":"int"},
{"name":"title","type":"string"},
{"name":"releaseDate","type":"string"},
]
}
|

Create Dataset
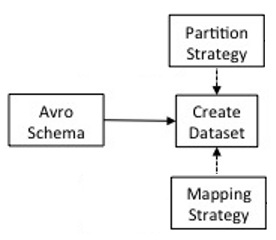
Once you have an Avro schema, you can create your dataset.
kite-dataset create movie --schema movie.avsc
Partition Strategy
In some cases, you can improve the performance of your dataset by creating logical partitions. For example, the Movie dataset could be partitioned by ID. Searches by ID would only search the containing folder, rather than the entire dataset. If you were searching for movie ID 3215, the search would be limited to the partition with records 3001-4000.
You define a partition strategy in JSON format. The following code sample defines the partition strategy movie.json for the Movie dataset.
Include the partition-by argument when you execute the create command.
kite-dataset create movie --schema movie.avsc partition-by movie.json
See Partitioned Datasets for more detail on partition strategies.
Column Mapping
Column mapping allows you to configure how your records should be stored in HBase for maximum performance and efficiency. You define the mapping based on the type of data you want to store, and Kite handles the infrastructure required to support your mapping strategy. See Column Mapping.
Parquet
If you typically work with a subset of the fields in your dataset rather than an entire row, you might want to create the dataset in Parquet format, rather than the default Avro format. See Parquet vs Avro Format.
kite-dataset create movie --schema movie.avsc -f parquet

Populate Dataset
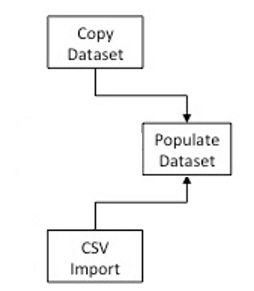
Once you create the dataset, you can insert data in a number of ways.
Import CSV
You can use the CLI command csv-import to insert records from a CSV file to your dataset.
kite-dataset csv-import /kite/example/movie.csv movie
See csv-import for additional options.
Copy Dataset
Use the copy command to transfer the contents of one dataset into another.
kite-dataset copy movie_parquet movie

Validate Dataset
Select the first few records of your dataset to ensure that they loaded properly. Use the show command to view the first 10 records in your dataset.
kite-dataset show movie
10 records is the default. You can set the number of records you want returned when you execute the command. For example, this would return the first 50 records.
kite-dataset show movie -n 50

Update Dataset
Loading Data
Once you have created your Kite dataset, you can add records as you would with any CDH dataset. If you use csv-import to add more records, they are appended to the dataset.
Compacting the Dataset
One by-product of the copy command is that it compacts multiple files in a partition into one file. This can be particularly useful for datasets that use streaming input. You can periodically copy the active dataset to an archive, or copy the dataset, delete the current data, and copy the compacted data back to the active dataset.
Updating the Dataset Schema
Over time, your dataset requirements might change. You can add, remove, or change the datatype of columns in your dataset, provided you don’t attempt a change that would result in the loss or corruption of data. Kite follows the guidelines for Schema resolution in the Avro spec. See Schema Evolution for more detail and examples.

Annihilate Dataset
When you first create a dataset, you might want to tweak it before you go live. It can be much cleaner and easier to delete the nascent dataset and start over. It could also be the case that your dataset is no longer needed. Regardless of your motivation, you can permanently remove one or more datasets from CDH using the CLI command delete.
For example, to remove the movies dataset, you can use the following command.
$ kite-dataset delete movies